六种概率数据结构的详细解释及应用场景

1/ Bloom Filter
- 用途: 测试一个元素是否可能在一个集合中。
- 原理: Bloom Filter 使用多个哈希函数将元素映射到一个位数组上。如果所有对应的位都被设置为1,则认为该元素可能在集合中。
- 优点: 非常节省空间,因为不需要存储实际的元素,只需存储位图信息。
- 应用: 在数据库查询优化、网页缓存过滤、网络路由器中快速判断是否转发数据包等场合都有应用。
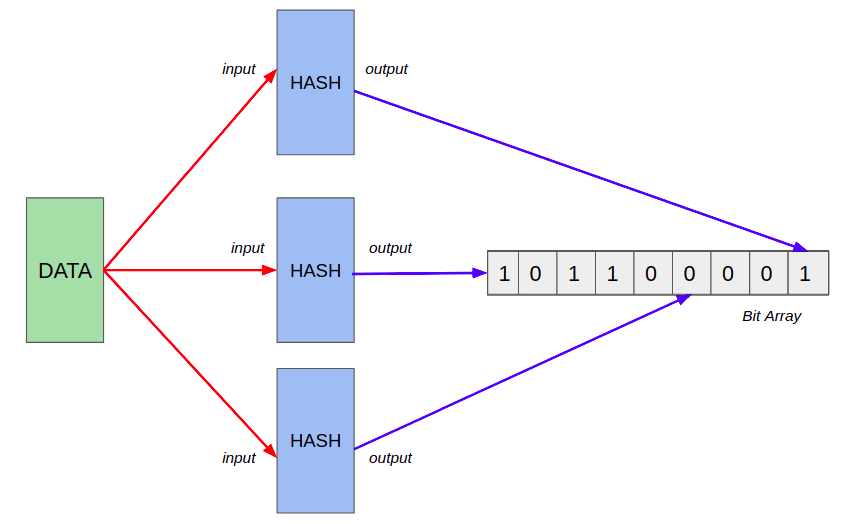
Bloom Filter在IP白名单
Bloom Filter 在 IP 白名单的应用场景主要是为了快速判断一个 IP 地址是否属于已知的白名单集合。由于 Bloom Filter 具有高效的存储和查询特性,它非常适合用于频繁查询的大规模数据集。例如,在网络防火墙或安全设备中,需要快速判断一个请求的来源 IP 是否属于预先定义好的白名单。
下面是一个使用 Guava 库实现 Bloom Filter 的示例代码,用于 IP 白名单检查:
示例代码
首先,确保你已经在项目中添加了 Guava 库的依赖。如果你使用的是 Maven,可以在 pom.xml 文件中添加如下依赖:
<dependency> <groupId>com.google.guava</groupId> <artifactId>guava</artifactId> <version>31.0.1-jre</version> </dependency>
然后,你可以使用以下 Java 代码来实现 IP 白名单的检查:
import com.google.common.hash.BloomFilter; import com.google.common.hash.Funnel; import java.net.InetAddress; import java.net.UnknownHostException; public class IPWhiteListExample { public static void main(String[] args) { // 创建一个BloomFilter实例,预期插入5000个元素,期望误报率为0.01 BloomFilter<InetAddress> ipBloomFilter = BloomFilter.create( new Funnel<InetAddress>() { @Override public void funnel(InetAddress from, com.google.common.hash.Hasher into) { into.putInt(from.getAddress().length); into.putBytes(from.getAddress()); } }, 5000, 0.01); // 添加一些IP地址到BloomFilter addIPToFilter(ipBloomFilter, "192.168.1.1"); addIPToFilter(ipBloomFilter, "192.168.1.2"); addIPToFilter(ipBloomFilter, "192.168.1.3"); // 检查IP地址是否存在于白名单中 checkIPInWhiteList(ipBloomFilter, "192.168.1.1"); // 应该返回true checkIPInWhiteList(ipBloomFilter, "192.168.1.4"); // 可能返回true或false,取决于误报率 } private static void addIPToFilter(BloomFilter<InetAddress> filter, String ipAddress) { try { InetAddress inetAddress = InetAddress.getByName(ipAddress); filter.put(inetAddress); } catch (UnknownHostException e) { e.printStackTrace(); } } private static void checkIPInWhiteList(BloomFilter<InetAddress> filter, String ipAddress) { try { InetAddress inetAddress = InetAddress.getByName(ipAddress); boolean mightBePresent = filter.mightContain(inetAddress); System.out.println("IP Address " + ipAddress + ": " + (mightBePresent ? "Might be in whitelist" : "Not in whitelist")); } catch (UnknownHostException e) { e.printStackTrace(); } } }
解释
- 创建 BloomFilter 实例:我们创建了一个 BloomFilter,预期插入 5000 个 IP 地址,期望的误报率为 0.01。
- 定义 Funnel:这里定义了一个 Funnel 接口实现,用于将 IP 地址转换为可哈希的形式。Funnel 接口允许我们指定如何将对象转换为原始类型以便进行哈希。
- 添加 IP 到 BloomFilter:我们通过
addIPToFilter方法将一些 IP 地址添加到 BloomFilter 中。 - 检查 IP 是否在白名单中:通过
checkIPInWhiteList方法,我们可以检查一个 IP 地址是否可能存在于白名单中。
这种方法非常适合用于需要快速判断 IP 地址是否合法的场景,例如在网络防火墙、负载均衡器或其他需要频繁进行 IP 地址验证的应用中。
在 Redis 中实现 Bloom Filter 可以利用 Redis 的 BitMap 数据类型或者 String 类型来存储位数组。Redis 本身并没有直接提供 Bloom Filter 的实现,但是可以通过手动构建位数组来模拟 Bloom Filter 的行为。
下面是如何使用 Redis 来实现一个 Bloom Filter,用于 IP 白名单过滤的场景:
步骤 1:安装 Redis 并连接
确保你已经安装了 Redis,并且有一个可用的 Redis 实例。同时,你需要一个 Redis 客户端库来与 Redis 交互。在 Java 中,可以使用 Jedis 或 Lettuce 库。这里我们将使用 Jedis。
添加 Jedis 依赖
如果你使用 Maven,可以在 pom.xml 文件中添加如下依赖:
<dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>4.4.0</version> </dependency>步骤 2:编写代码
接下来,编写 Java 代码来实现 Bloom Filter,并用于 IP 白名单检查。
示例代码
import redis.clients.jedis.Jedis; import java.security.MessageDigest; import java.security.NoSuchAlgorithmException; import java.util.Arrays; import java.util.stream.IntStream; public class RedisBloomFilterExample { private static final int BLOOM_FILTER_SIZE = 10000; // 位数组大小 private static final int HASH_FUNCTIONS_COUNT = 5; // 哈希函数的数量 public static void main(String[] args) { // 连接 Redis Jedis jedis = new Jedis("localhost", 6379); // 替换为实际的 Redis 地址和端口 // 清空 Redis 数据库(仅用于演示) jedis.flushDB(); // 添加 IP 地址到 Bloom Filter addIPToFilter(jedis, "192.168.1.1"); addIPToFilter(jedis, "192.168.1.2"); addIPToFilter(jedis, "192.168.1.3"); // 检查 IP 地址是否在白名单中 checkIPInWhiteList(jedis, "192.168.1.1"); // 应该返回 true checkIPInWhiteList(jedis, "192.168.1.4"); // 可能返回 true 或 false,取决于误报率 } private static void addIPToFilter(Jedis jedis, String ipAddress) { byte[] ipBytes = ipToByteArray(ipAddress); IntStream.range(0, HASH_FUNCTIONS_COUNT).forEach(i -> { int index = hash(ipBytes, i) % BLOOM_FILTER_SIZE; jedis.setbit("bloomfilter", index, true); }); } private static void checkIPInWhiteList(Jedis jedis, String ipAddress) { byte[] ipBytes = ipToByteArray(ipAddress); boolean mightBePresent = IntStream.range(0, HASH_FUNCTIONS_COUNT) .allMatch(i -> jedis.getbit("bloomfilter", hash(ipBytes, i) % BLOOM_FILTER_SIZE)); System.out.println("IP Address " + ipAddress + ": " + (mightBePresent ? "Might be in whitelist" : "Not in whitelist")); } private static byte[] ipToByteArray(String ipAddress) { try { return InetAddress.getByName(ipAddress).getAddress(); } catch (UnknownHostException e) { throw new RuntimeException(e); } } private static int hash(byte[] data, int seed) { int hash = 0; MessageDigest md = null; try { md = MessageDigest.getInstance("MD5"); } catch (NoSuchAlgorithmException e) { throw new RuntimeException(e); } md.update(data); byte[] digest = md.digest(); hash = seed * digest[0] & 0xFF; return Math.abs(hash); } }注意事项
- 哈希函数:这里的哈希函数使用 MD5 消息摘要算法,但在实际应用中可以根据需要选择其他哈希算法。
- 位数组大小和哈希函数数量:
BLOOM_FILTER_SIZE和HASH_FUNCTIONS_COUNT的选择会影响 Bloom Filter 的误报率和存储效率。你可以根据实际需求调整这两个参数。 - 误报率:Bloom Filter 存在一定的误报率,因此在判断 IP 地址是否在白名单中时,需要考虑这一点。
通过上述步骤,你可以在 Redis 中实现一个 Bloom Filter,并用于 IP 白名单过滤的场景。这种方法特别适合需要快速查询大量 IP 地址的应用场景。
2/ Cuckoo Filter:
- 用途: 类似于Bloom Filter,测试一个元素是否可能在一个集合中。
- 原理: Cuckoo Filter 使用类似于Cuckoo Hashing的技术来存储元素的指纹(通常是哈希值的一部分),并允许删除操作。
- 优点: 支持删除操作,并且在某些情况下性能优于Bloom Filter。
- 应用: 在数据库系统中用于快速查询以及在网络环境中进行快速过滤等。
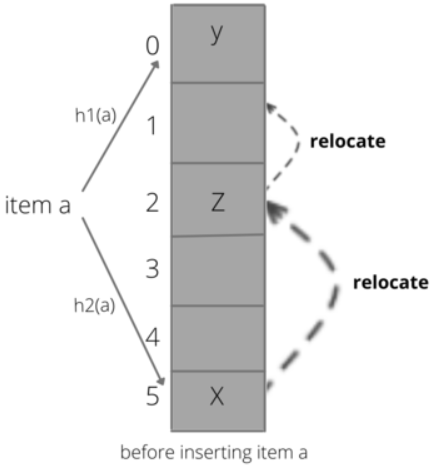
Cuckoo Filter 使用指纹来存储元素的一部分信息,并使用 Cuckoo Hashing 来解决冲突。在电商系统中,Cuckoo Filter 可以用于多种场景,如缓存键管理、商品推荐系统中的去重、用户行为分析等。
应用场景示例
缓存键管理:在电商系统的缓存机制中,可以使用 Cuckoo Filter 来存储已存在的缓存键,从而快速判断一个新键是否已经存在于缓存中,避免不必要的缓存查找。
商品推荐系统中的去重:在推荐系统中,可以使用 Cuckoo Filter 来存储已推荐的商品 ID,确保不会重复推荐相同的产品。
用户行为分析:在用户行为跟踪和分析中,可以使用 Cuckoo Filter 来记录用户的浏览历史记录,从而快速判断用户是否浏览过某个特定的商品。
使用 Java 编写 Cuckoo Filter 示例
在 Java 中,可以使用第三方库来实现 Cuckoo Filter,比如 cuckoofilter 库。下面是一个使用 cuckoofilter 库的示例代码,展示如何在电商系统中使用 Cuckoo Filter 进行缓存键管理。
步骤 1:添加依赖
首先,确保你在项目中添加了 cuckoofilter 库的依赖。如果你使用 Maven,可以在 pom.xml 文件中添加如下依赖:
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>cuckoofilter</artifactId>
<version>1.1.0</version>
</dependency>步骤 2:编写代码
接下来,编写 Java 代码来实现 Cuckoo Filter,并用于缓存键管理的场景。
import com.github.xiaoymin.cuckoofilter.CuckooFilter; import com.github.xiaoymin.cuckoofilter.CuckooFilterBuilder; import com.github.xiaoymin.cuckoofilter.CuckooFilterPolicy; import com.github.xiaoymin.cuckoofilter.CuckooFilterType; import java.nio.charset.StandardCharsets; import java.util.Arrays; public class CuckooFilterDemo { public static void main(String[] args) { // 创建 Cuckoo Filter 实例,预期插入 10000 个元素,误报率为 0.01 CuckooFilter<String> cuckooFilter = new CuckooFilterBuilder<String>() .type(CuckooFilterType.LFU) .policy(CuckooFilterPolicy.DOUBLE_HASHING) .expectedInsertions(10000) .fpp(0.01) .build(); // 添加一些缓存键到 Cuckoo Filter addCacheKeyToFilter(cuckooFilter, "product:123"); addCacheKeyToFilter(cuckooFilter, "product:456"); addCacheKeyToFilter(cuckooFilter, "product:789"); // 检查缓存键是否存在于 Cuckoo Filter 中 checkCacheKeyInFilter(cuckooFilter, "product:123"); // 应该返回 true checkCacheKeyInFilter(cuckooFilter, "product:000"); // 可能返回 true 或 false,取决于误报率 } private static void addCacheKeyToFilter(CuckooFilter<String> filter, String cacheKey) { byte[] keyBytes = cacheKey.getBytes(StandardCharsets.UTF_8); filter.insert(keyBytes); } private static void checkCacheKeyInFilter(CuckooFilter<String> filter, String cacheKey) { byte[] keyBytes = cacheKey.getBytes(StandardCharsets.UTF_8); boolean mightBePresent = filter.mightContain(keyBytes); System.out.println("Cache Key " + cacheKey + ": " + (mightBePresent ? "Might be in cache" : "Not in cache")); } }
通过上述示例,你可以看到如何使用 cuckoofilter 库在 Java 中实现 Cuckoo Filter,并将其应用于电商系统的缓存键管理场景。Cuckoo Filter 的优势在于支持删除操作,并且具有较高的精确度,非常适合需要快速判断元素是否存在的情况。3/ HyperLogLog:
- 用途: 计算数据流中的唯一元素数量。
- 原理: HyperLogLog 使用特殊的哈希函数和统计方法来估计不同元素的数量。
- 优点: 非常节省内存,对于大数据集尤其有用。
- 应用: 在大数据分析领域用于计算唯一访问者数(如网站UV)、网络流量分析等。
应用场景示例
- 唯一访问者统计:可以使用 HyperLogLog 来估计每天或每小时的独立访客数(UV)。
- 唯一商品点击统计:可以用来估算某段时间内被点击过的不同商品的数量。
- 唯一搜索关键词统计:可以用来统计一段时间内用户搜索的不同关键词的数量。
使用 Java 编写 HyperLogLog 示例
在 Java 中,可以使用第三方库来实现 HyperLogLog。一个常用的库是 google/guava,它提供了 HyperLogLog 的实现。下面是一个使用 Guava 库的示例代码,展示如何在电商系统中使用 HyperLogLog 来统计独立访客数(UV)。
接下来,编写 Java 代码来实现 HyperLogLog,并用于统计独立访客数的场景
import com.google.common.primitives.Ints; import com.google.common.primitives.UnsignedLong; import com.google.common.hash.HyperLogLog; import com.google.common.hash.HyperLogLogCounter; import java.util.UUID; public class HyperLogLogExample { public static void main(String[] args) { // 创建 HyperLogLog 实例,预期误差率大约为 2% HyperLogLog hyperLogLog = HyperLogLog.newCounterBuilder() .withExpectedNumElements(100000) .withFpp(0.02) .build(); // 模拟独立访客数 int numberOfVisitors = 100000; for (int i = 0; i < numberOfVisitors; i++) { String visitorId = UUID.randomUUID().toString(); // 模拟每个访客的唯一标识符 hyperLogLog.offer(UnsignedLong.fromIntBits(visitorId.hashCode())); } // 输出估计的独立访客数 System.out.println("Estimated number of unique visitors: " + hyperLogLog.count()); } }
通过上述示例,你可以看到如何使用 Guava 库在 Java 中实现 HyperLogLog,并将其应用于电商系统的独立访客数统计场景。HyperLogLog 的优点在于它可以非常节省内存,同时提供一个足够准确的基数估计,非常适合需要处理大规模数据集并且对精确度要求不是极高的场景。例如,在实时监控、流量统计、日志分析等领域都有广泛的应用。
Redis 自版本 2.8.9 起引入了 HyperLogLog 数据结构,专门用于估计集合中的不同元素数量。HyperLogLog 在 Redis 中的实现非常高效,特别适合于统计独立访客(UV)、唯一关键词等场景。
示例:使用 Redis 的 HyperLogLog 统计 UV
import redis.clients.jedis.Jedis; public class RedisHyperLogLogExample { public static void main(String[] args) { Jedis jedis = new Jedis("localhost", 6379); jedis.flushDB(); // 清空数据库(仅用于演示) // 假设这是来自用户的请求,我们记录每个用户的唯一标识符 String[] userIds = {"user1", "user2", "user3", "user1", "user4"}; // 将用户标识符添加到 HyperLogLog 中 for (String userId : userIds) { jedis.pfAdd("unique_visitors", userId); } // 获取估计的独立访客数 long estimatedUniqueVisitors = jedis.pfCount("unique_visitors"); System.out.println("Estimated number of unique visitors: " + estimatedUniqueVisitors); } }
4/ Count-Min Sketch:
- 用途: 估计数据流中事件的频率。
- 原理: 使用多个哈希函数将元素映射到二维数组(或计数矩阵)中的位置,并增加计数器。
- 优点: 节省空间,可以快速得到近似的频率信息。
- 应用: 在网络监控中用来跟踪流量模式,在搜索引擎中估算关键词频率,在数据库系统中进行聚合查询加速等。
应用场景示例
- 商品点击频率统计:可以使用 CMS 来统计哪些商品被点击最多,帮助进行商品推荐或广告投放。
- 用户行为模式分析:可以用来分析用户对于特定商品类别的偏好,帮助改进商品分类或个性化推荐。
- 热门关键词统计:可以用来统计用户搜索中最常出现的关键词,帮助优化搜索引擎或内容推荐。
使用 Java 编写 Count-Min Sketch 示例
为了实现 Count-Min Sketch,在 Java 中可以自行实现 CMS 的逻辑,或者使用第三方库。这里我们提供一个简单的 CMS 实现示例。
步骤 1:定义 CMS 类
首先,我们需要定义一个 CMS 类,用于初始化矩阵和哈希函数。
import java.util.Arrays; public class CountMinSketch { private int width; private int depth; private int[][] matrix; private HashFunction[] hashFunctions; public CountMinSketch(int width, int depth) { this.width = width; this.depth = depth; this.matrix = new int[depth][width]; this.hashFunctions = new HashFunction[depth]; // 初始化哈希函数 for (int i = 0; i < depth; i++) { hashFunctions[i] = new HashFunction(width); } } public void update(String item, int increment) { for (HashFunction f : hashFunctions) { int index = f.hash(item); matrix[f.getIndex()][index] += increment; } } public int estimate(String item) { int minEstimate = Integer.MAX_VALUE; for (HashFunction f : hashFunctions) { int index = f.hash(item); minEstimate = Math.min(minEstimate, matrix[f.getIndex()][index]); } return minEstimate; } private class HashFunction { private int a; private int b; private int m; public HashFunction(int width) { this.a = (int) (Math.random() * width); this.b = (int) (Math.random() * width); this.m = width; } public int hash(String item) { return ((a * item.hashCode() + b) % m + m) % m; // 防止负数 } public int getIndex() { return Arrays.asList(this).indexOf(this); } } }
步骤 2:使用 CMS 类
接下来,编写 Java 代码来使用上面定义的 CMS 类,并用于统计电商系统中的商品点击频率。
public class CountMinSketchExample { public static void main(String[] args) { // 创建 Count-Min Sketch 实例 CountMinSketch cms = new CountMinSketch(1000, 5); // 模拟商品点击事件 String[] products = {"ProductA", "ProductB", "ProductC"}; for (String product : products) { for (int i = 0; i < 1000; i++) { cms.update(product, 1); // 更新 CMS 计数器 } } // 输出估计的商品点击次数 System.out.println("Estimated clicks for ProductA: " + cms.estimate("ProductA")); System.out.println("Estimated clicks for ProductB: " + cms.estimate("ProductB")); System.out.println("Estimated clicks for ProductC: " + cms.estimate("ProductC")); } }
通过上述示例,你可以看到如何在 Java 中实现 Count-Min Sketch,并将其应用于电商系统中的商品点击频率统计场景。Count-Min Sketch 的主要优势在于能够以较小的内存消耗提供元素频率的近似估计,适用于需要快速统计大量数据的情况。不过需要注意的是,CMS 提供的是估计值,并非精确值,因此在需要精确统计的情况下可能不适合。
Redis 没有直接支持 Count-Min Sketch,但可以使用 Redis 的哈希表(Hashes)或有序集合(Sorted Sets)来实现 CMS 的矩阵和哈希函数逻辑。
示例:使用 Redis 的 Hashes 模拟 Count-Min Sketch
import redis.clients.jedis.Jedis; public class RedisCountMinSketchExample { public static void main(String[] args) { Jedis jedis = new Jedis("localhost", 6379); jedis.flushDB(); // 清空数据库(仅用于演示) // 假设 CMS 的宽度为 1000,深度为 5 int width = 1000; int depth = 5; String prefix = "cms_layer_"; // 模拟商品点击事件 String[] products = {"ProductA", "ProductB", "ProductC"}; for (String product : products) { for (int i = 0; i < 1000; i++) { updateCountMinSketch(jedis, product, 1, width, depth, prefix); } } // 输出估计的商品点击次数 System.out.println("Estimated clicks for ProductA: " + estimateFrequency(jedis, "ProductA", width, depth, prefix)); System.out.println("Estimated clicks for ProductB: " + estimateFrequency(jedis, "ProductB", width, depth, prefix)); System.out.println("Estimated clicks for ProductC: " + estimateFrequency(jedis, "ProductC", width, depth, prefix)); } private static void updateCountMinSketch(Jedis jedis, String item, int increment, int width, int depth, String prefix) { for (int layer = 0; layer < depth; layer++) { int index = hash(item, layer, width); String key = prefix + layer; jedis.hincrBy(key, String.valueOf(index), increment); } } private static long estimateFrequency(Jedis jedis, String item, int width, int depth, String prefix) { long minEstimate = Long.MAX_VALUE; for (int layer = 0; layer < depth; layer++) { int index = hash(item, layer, width); String key = prefix + layer; long value = jedis.hget(key, String.valueOf(index)) == null ? 0 : Long.parseLong(jedis.hget(key, String.valueOf(index))); minEstimate = Math.min(minEstimate, value); } return minEstimate; } private static int hash(String item, int layer, int modulo) { int a = layer; int b = layer * 2; return ((a * item.hashCode() + b) % modulo + modulo) % modulo; // 防止负数 } }
5/ MinHash:
- 用途: 估计两个集合之间的相似度。
- 原理: MinHash 对集合中的元素应用哈希函数,产生签名,通过比较签名来估计Jaccard相似度。
- 优点: 在处理大规模数据集时效率高,可以有效地计算相似性。
- 应用: 在文档检索系统中检测重复文档,在推荐系统中计算用户兴趣相似度,在反垃圾邮件系统中检测垃圾邮件集群等。
使用 MinHash 进行商品推荐
在这个例子中,我们将展示如何使用 MinHash 来检测用户购物篮中的商品相似性,并据此进行商品推荐。
步骤 1:定义 MinHash 类
首先,我们需要定义一个 MinHash 类来实现 MinHash 的逻辑。
import java.util.ArrayList; import java.util.List; import java.util.Random; public class MinHash { private List<Integer> signatureMatrix; private int numPermutations; public MinHash(int numPermutations) { this.numPermutations = numPermutations; this.signatureMatrix = new ArrayList<>(); for (int i = 0; i < numPermutations; i++) { signatureMatrix.add(Integer.MAX_VALUE); } } public void updateSignature(List<Integer> shingleIds) { Random rand = new Random(); for (int i = 0; i < numPermutations; i++) { int a = rand.nextInt(numPermutations); int b = rand.nextInt(numPermutations); for (int shingleId : shingleIds) { int hashedValue = (a * shingleId + b) % numPermutations; if (hashedValue < signatureMatrix.get(i)) { signatureMatrix.set(i, hashedValue); } } } } public List<Integer> getSignature() { return signatureMatrix; } }
步骤 2:创建商品数据模型
接着,我们需要创建一个简单的数据模型来表示商品和用户的购物篮。
import java.util.HashSet; import java.util.Set; public class ShoppingCart { private Set<Integer> items; public ShoppingCart() { this.items = new HashSet<>(); } public void addItem(int itemId) { items.add(itemId); } public Set<Integer> getItems() { return items; } }
步骤 3:使用 MinHash 进行商品推荐
现在,我们可以编写一个主程序来使用 MinHash 来检测用户购物篮中的商品相似性,并据此进行商品推荐。
import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; public class MinHashExample { public static void main(String[] args) { // 创建 MinHash 实例 int numPermutations = 100; MinHash minHashUser1 = new MinHash(numPermutations); MinHash minHashUser2 = new MinHash(numPermutations); // 创建用户购物篮 ShoppingCart shoppingCartUser1 = new ShoppingCart(); ShoppingCart shoppingCartUser2 = new ShoppingCart(); // 模拟用户购物篮数据 shoppingCartUser1.addItem(1); shoppingCartUser1.addItem(2); shoppingCartUser1.addItem(3); shoppingCartUser1.addItem(4); shoppingCartUser2.addItem(2); shoppingCartUser2.addItem(3); shoppingCartUser2.addItem(5); // 转换购物篮数据为 Shingle ID 列表 List<Integer> shingleIdsUser1 = new ArrayList<>(shoppingCartUser1.getItems()); List<Integer> shingleIdsUser2 = new ArrayList<>(shoppingCartUser2.getItems()); // 更新 MinHash 签名 minHashUser1.updateSignature(shingleIdsUser1); minHashUser2.updateSignature(shingleIdsUser2); // 计算 Jaccard 相似度 double jaccardSimilarity = calculateJaccardSimilarity(minHashUser1.getSignature(), minHashUser2.getSignature()); System.out.println("Jaccard Similarity between User 1 and User 2: " + jaccardSimilarity); // 根据相似性推荐商品 recommendProductsBasedOnSimilarity(shoppingCartUser1, shoppingCartUser2); } private static double calculateJaccardSimilarity(List<Integer> sig1, List<Integer> sig2) { int matches = 0; for (int i = 0; i < sig1.size(); i++) { if (sig1.get(i).equals(sig2.get(i))) { matches++; } } return (double) matches / sig1.size(); } private static void recommendProductsBasedOnSimilarity(ShoppingCart user1, ShoppingCart user2) { Set<Integer> user1Items = user1.getItems(); Set<Integer> user2Items = user2.getItems(); // 找出用户 2 拥有但用户 1 没有的商品 user2Items.removeAll(user1Items); System.out.println("Recommended products for User 1 based on User 2's basket:"); user2Items.forEach(itemId -> System.out.println("Item ID: " + itemId)); } }
代码解释
定义 MinHash 类:
updateSignature方法用于更新 MinHash 签名矩阵。getSignature方法用于获取签名矩阵。
创建商品数据模型:
ShoppingCart类用于表示用户的购物篮,其中包含用户购买的商品 ID。
使用 MinHash 进行商品推荐:
- 创建两个用户的购物篮,并填充一些商品 ID。
- 将购物篮数据转换为 Shingle ID 列表,并更新 MinHash 签名。
- 计算两个用户的 Jaccard 相似度。
- 根据相似性推荐商品,找出用户 2 拥有但用户 1 没有的商品,并推荐给用户 1。
通过上述示例,你可以看到如何在 Java 中实现 MinHash,并将其应用于电商系统中的商品推荐场景。MinHash 的主要优点在于它能够有效地处理大数据集,并快速估计集合之间的相似性,这对于推荐系统来说是非常有用的特性。在实际应用中,还可以结合 LSH (Locality Sensitive Hashing) 技术来进一步提高相似性检测的效率。
Redis 可以用来存储 MinHash 签名,例如使用字符串类型来存储签名,或者使用哈希表来存储多个签名。
示例:使用 Redis 的 Hashes 模拟 MinHash
import redis.clients.jedis.Jedis; public class RedisMinHashExample { public static void main(String[] args) { Jedis jedis = new Jedis("localhost", 6379); jedis.flushDB(); // 清空数据库(仅用于演示) // 假设 MinHash 的宽度为 100 int width = 100; String prefix = "min_hash_"; // 模拟用户购物篮数据 String[] itemsUser1 = {"item1", "item2", "item3"}; String[] itemsUser2 = {"item2", "item3", "item4"}; // 更新 MinHash 签名 updateMinHash(jedis, "user1", itemsUser1, width, prefix); updateMinHash(jedis, "user2", itemsUser2, width, prefix); // 计算 Jaccard 相似度 double jaccardSimilarity = calculateJaccardSimilarity(jedis, "user1", "user2", width, prefix); System.out.println("Jaccard Similarity between User 1 and User 2: " + jaccardSimilarity); } private static void updateMinHash(Jedis jedis, String user, String[] items, int width, String prefix) { String key = prefix + user; for (int i = 0; i < width; i++) { int minIndex = Integer.MAX_VALUE; for (String item : items) { int index = hash(item, i, width); minIndex = Math.min(minIndex, index); } jedis.hset(key, String.valueOf(i), String.valueOf(minIndex)); } } private static double calculateJaccardSimilarity(Jedis jedis, String user1, String user2, int width, String prefix) { String key1 = prefix + user1; String key2 = prefix + user2; int matches = 0; for (int i = 0; i < width; i++) { String val1 = jedis.hget(key1, String.valueOf(i)); String val2 = jedis.hget(key2, String.valueOf(i)); if (val1 != null && val2 != null && val1.equals(val2)) { matches++; } } return (double) matches / width; } private static int hash(String item, int layer, int modulo) { int a = layer; int b = layer * 2; return ((a * item.hashCode() + b) % modulo + modulo) % modulo; // 防止负数 } }
6/ Skip List:
- 用途: 提供了一种有序的数据结构,支持快速查找、插入和删除操作。
- 原理: Skip List 是一种基于链表的数据结构,它通过多层链接列表实现跳跃机制,每一层都会跳过一定数量的节点。
- 优点: 相比平衡树更容易实现,同时提供了对数级别的性能。
- 应用: 在内存管理中实现高效的数据排序,在数据库管理系统中提供索引功能等。
示例:使用 Skip List 进行商品评分排序
在这个例子中,我们将展示如何使用跳跃列表来实现商品评分的排序功能。我们将会使用 Java 生态中的 ConcurrentSkipListMap 类来实现这个功能。
import java.util.Comparator; import java.util.concurrent.ConcurrentSkipListMap; public class SkipListExample { public static void main(String[] args) { // 创建一个带有自定义比较器的 ConcurrentSkipListMap ConcurrentSkipListMap<ProductRatingPair, Product> productRatingMap = new ConcurrentSkipListMap<>(new Comparator<ProductRatingPair>() { @Override public int compare(ProductRatingPair o1, ProductRatingPair o2) { return Integer.compare(o1.getRating(), o2.getRating()); // 按照评分降序排列 } }); // 模拟商品及其评分数据 Product product1 = new Product("Product A", 4); Product product2 = new Product("Product B", 3); Product product3 = new Product("Product C", 5); Product product4 = new Product("Product D", 2); // 添加商品到跳跃列表 productRatingMap.put(new ProductRatingPair(product1.getName(), product1.getRating()), product1); productRatingMap.put(new ProductRatingPair(product2.getName(), product2.getRating()), product2); productRatingMap.put(new ProductRatingPair(product3.getName(), product3.getRating()), product3); productRatingMap.put(new ProductRatingPair(product4.getName(), product4.getRating()), product4); // 输出所有商品按评分排序后的结果 System.out.println("Sorted Products by Rating:"); for (ProductRatingPair key : productRatingMap.keySet()) { Product product = productRatingMap.get(key); System.out.println(product.getName() + " with rating " + product.getRating()); } // 查找评分大于等于 3 的商品 System.out.println("\nProducts with rating >= 3:"); for (ProductRatingPair key : productRatingMap.subMap(new ProductRatingPair("", 3), true, new ProductRatingPair("", 5), true).keySet()) { Product product = productRatingMap.get(key); System.out.println(product.getName() + " with rating " + product.getRating()); } } static class Product { private String name; private int rating; public Product(String name, int rating) { this.name = name; this.rating = rating; } public String getName() { return name; } public int getRating() { return rating; } } static class ProductRatingPair { private String productName; private int rating; public ProductRatingPair(String productName, int rating) { this.productName = productName; this.rating = rating; } public String getProductName() { return productName; } public int getRating() { return rating; } } }
通过上述示例,你可以看到如何使用 Java 生态中的 ConcurrentSkipListMap 类来实现跳跃列表,并将其应用于电商系统中的商品评分排序场景。跳跃列表的优点在于它提供了高效的查找、插入和删除操作,并且在并发环境下也能保证线程安全。这对于需要频繁更新和查询商品评分的电商系统来说是非常有用的。Redis 使用了跳跃列表(Skip List)作为其有序集合(Sorted Set)的底层实现之一。当元素数量较少时,Redis 使用字典(哈希表)来存储有序集合;当元素数量增加到一定程度时,Redis 会自动切换到跳跃列表来存储有序集合,以便更有效地支持范围查询和排序。在电商系统中,有序集合(Sorted Set)可以被广泛应用于需要根据某个分数(score)对元素进行排序的场景。
总结
以上每种数据结构都有其独特的使用场景和优势,作为工程师了解它们可以让你在面对特定问题时做出更好的技术选择。
今天先到这儿,希望对云原生,技术领导力, 企业管理,系统架构设计与评估,团队管理, 项目管理, 产品管理,信息安全,团队建设 有参考作用 , 您可能感兴趣的文章:
构建创业公司突击小团队
国际化环境下系统架构演化
微服务架构设计
视频直播平台的系统架构演化
微服务与Docker介绍
Docker与CI持续集成/CD
互联网电商购物车架构演变案例
互联网业务场景下消息队列架构
互联网高效研发团队管理演进之一
消息系统架构设计演进
互联网电商搜索架构演化之一
企业信息化与软件工程的迷思
企业项目化管理介绍
软件项目成功之要素
人际沟通风格介绍一
精益IT组织与分享式领导
学习型组织与企业
企业创新文化与等级观念
组织目标与个人目标
初创公司人才招聘与管理
人才公司环境与企业文化
企业文化、团队文化与知识共享
高效能的团队建设
项目管理沟通计划
构建高效的研发与自动化运维
某大型电商云平台实践
互联网数据库架构设计思路
IT基础架构规划方案一(网络系统规划)
餐饮行业解决方案之客户分析流程
餐饮行业解决方案之采购战略制定与实施流程
餐饮行业解决方案之业务设计流程
供应链需求调研CheckList
企业应用之性能实时度量系统演变
如有想了解更多软件设计与架构, 系统IT,企业信息化, 团队管理 资讯,请关注我的微信订阅号:

作者:Petter Liu
出处:http://www.cnblogs.com/wintersun/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
该文章也同时发布在我的独立博客中-Petter Liu Blog。