DolphinScheduler 3.3.0版本更新一览
Apache DolphinScheduler即将迎来3.3.0版本的发布,届时将有一系列重要的更新和改进。在近期的社区5月份用户线上分享会上,项目PMC 阮文俊为大家介绍了3.3.0版本将带来的主要更新和改进,并为大家指出了如何参与社区的方式。
什么是DolphinScheduler?
DolphinScheduler是一个开源的项目,主要用来进行工作流编排、运行和管理。
它有四个重要的特点:
- 工作流是基本单位,所有的功能设计都是围绕工作流
- 这是一个低代码平台,可以不用代码,或用少量的代码来完成工作流相关的工作
- 不用数据迁移即可进行服务器节点的扩缩容
- 采用插件化架构
工作流是基本单位
- 工作流可以包含任务和子工作流,每个任务都需要属于一个工作流。
- 工作流可以依赖其他工作流,工作流是最小的执行单元。
- 工作流的执行支持手动或自动触发。

无/低代码操作
- 可以在UI门户,通过页面托拉拽的交互方式完成工作流的定义和管控操作;
- 也可以通过OpenAPI或PyDolphinScheduler来完成对工作流的相关操作。

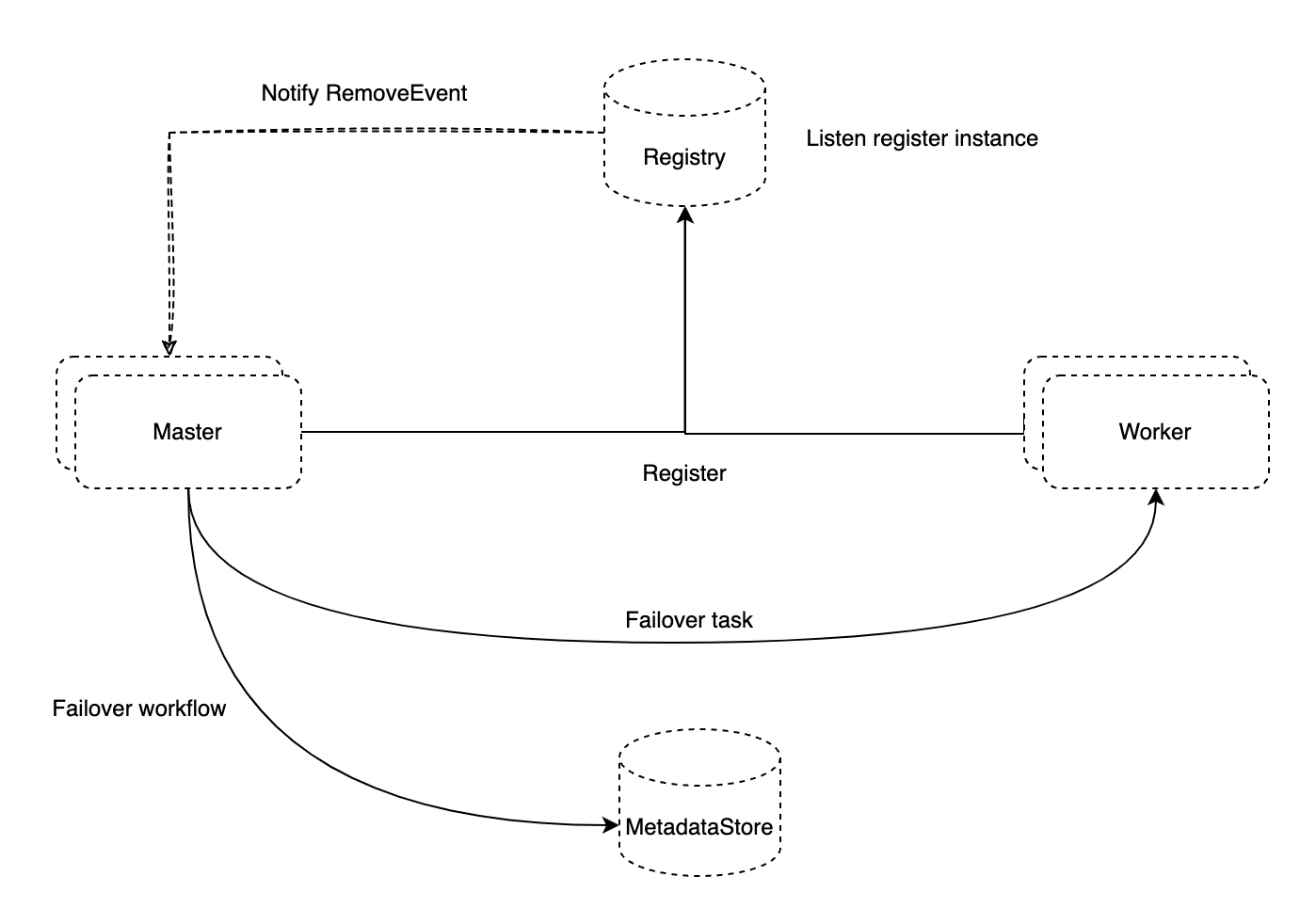
无需数据迁移进行扩缩容
- 元数据存储在共享的关系数据库中,无需数据迁移即可扩展系统。
- 服务上线时自动注册到集群,服务下线时,运行中的任务自动转移,无需人工介入。

插件化架构
- 工作流引擎之外的组件以插件形式实现。
- 报警插件:Email、Http、微信、Slack等
- 任务插件:Shell, SQL, Spark, K8s等
- 数据源插件:Mysql, PG, Oracle等
- 支持Zookeeper、JDBC、ETCD作为注册中心
- 支持HDFS、S3、OSS等存储系统
接下来看一下3.3.0版本中有哪些新的变化。
3.3.0版本更新一览
架构更新
3.3.0版本在整体架构和部署方式上没有太大的变化,依然是三个核心服务:API主要用来做一些源数据的管理和授权方面的事情,Master主要是用来做工作流的编排和执行,Worker主要用来做任务的执行和管控。大部份核心组件通过插件的方式被加载。

新版中的一些重大变化包括:
新的任务插件接口
之前的版本在任务插件定义上有着如下问题:
- 任务插件中的方法与生命周期不匹配,在任务插件定义上没有暴露生命周期的方法,导致任务插件实现时会缺失,暂停、容错等控制方法。。
- 目前的任务插件接口过于复杂,任务插件接口包含很多子插件的方法,导致任务插件接口越来越膨胀。
3.3.0版本将引入新的任务插件定义接口(V2版本)来管理任务插件实例的生命周期。任务插件实例的生命周期管理包括运行、暂停、杀死、容错、成功和失败状态。
新的任务插件接口会更加清晰明了:

- 增加ITaskApplicationContext:表示任务插件实例运行的上下文信息,例如 processId、applicationId
- 增加ITaskListenerManager:可以注册用于侦听任务插件实例的信息更改,便于对任务执行流程进行扩展
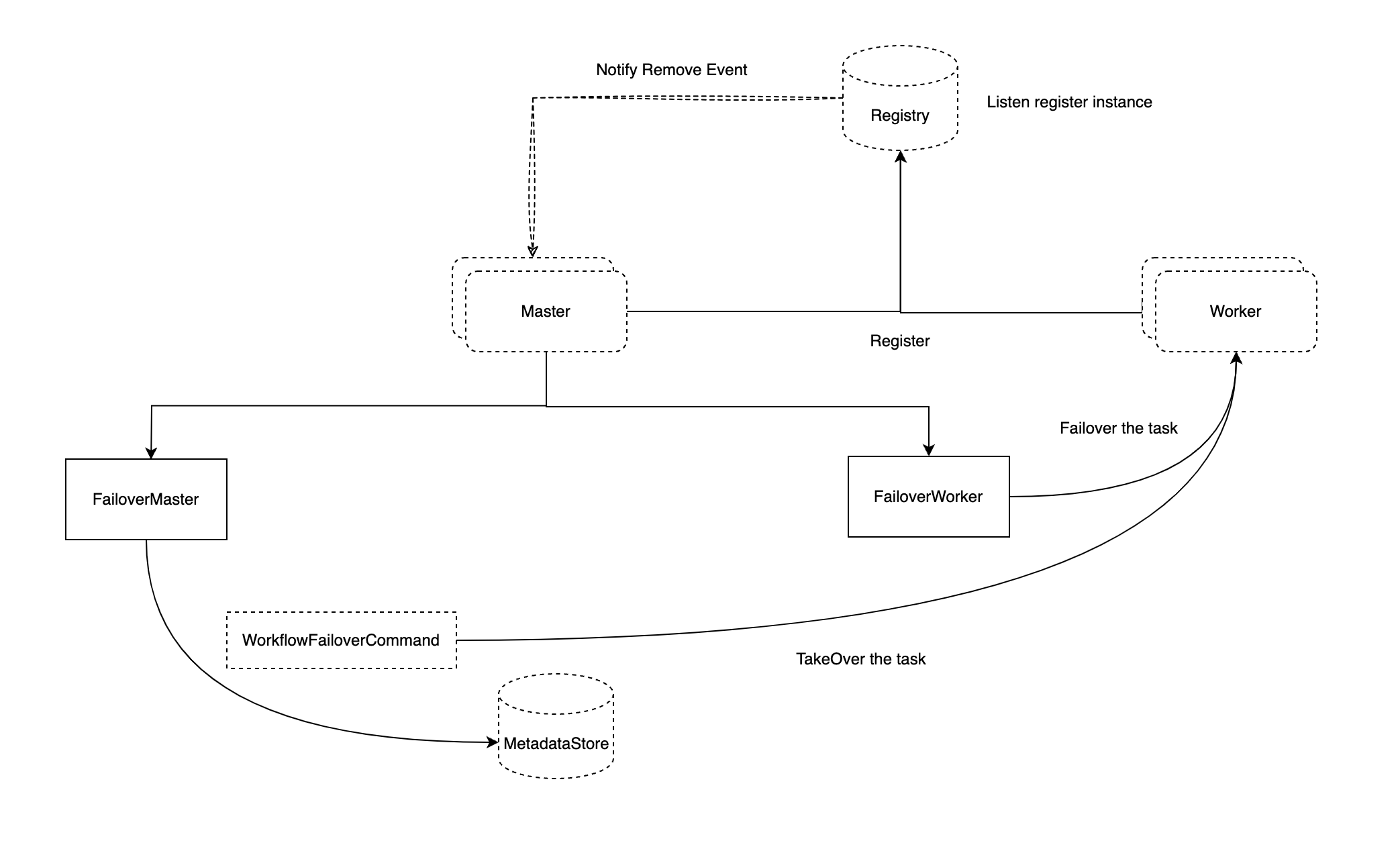
容错改进
- Master容错:
- 对下线的Master节点持有的工作流程进行容错
- 插入工作流容错命令
- 工作流容错将从Worker服务器接管正在运行的任务
- Worker容错:
- 处理下线的Worker节点运行的任务
- 把容错任务分发给新的Worker节点
- 不同的任务插件的容错行为可能会不同
- 支持精确一次(exactly-once)、至少一次(at-least-once)、至多一次(at-most-once)的容错行为
参数优先级统一
此前,DolphinScheduler中有多重参数类型,包括启动参数、工作流定义参数、任务定义参数、租户参数等,但存在的问题是这些参数没有统一的优先级,有些参数在运行时无法更改。
在3.3.0版本中,我们对参数优先级进行了优化:
- 统一了参数优先级,遵循就近原则,如启动参数 > 任务定义参数 > 工作流定义参数。
- 启动参数优先级最高,其他参数可被启动参数覆盖,解决了参数优先级不一致以及某些参数无法在运行时更改的问题。
工作流触发解耦
目前,DolphinScheduler中所有工作流触发都通过命令表示。目前的方式存在以下弊端:
- 只能在数据库中插入触发命令,trigger与数据库严格绑定
- 没有触发命令的schema,难以扩展新的触发
新版本对工作流触发进行了解耦,并可以通过消息中间件来进行工作流触发:
- 提供了标准的Trigger schema,方便扩展trigger
- 引入CommandEngine组件来探测待处理的命令
- 命令的repository不再仅限于关系型数据库,支持从流式系统(如Kafka)中消费命令
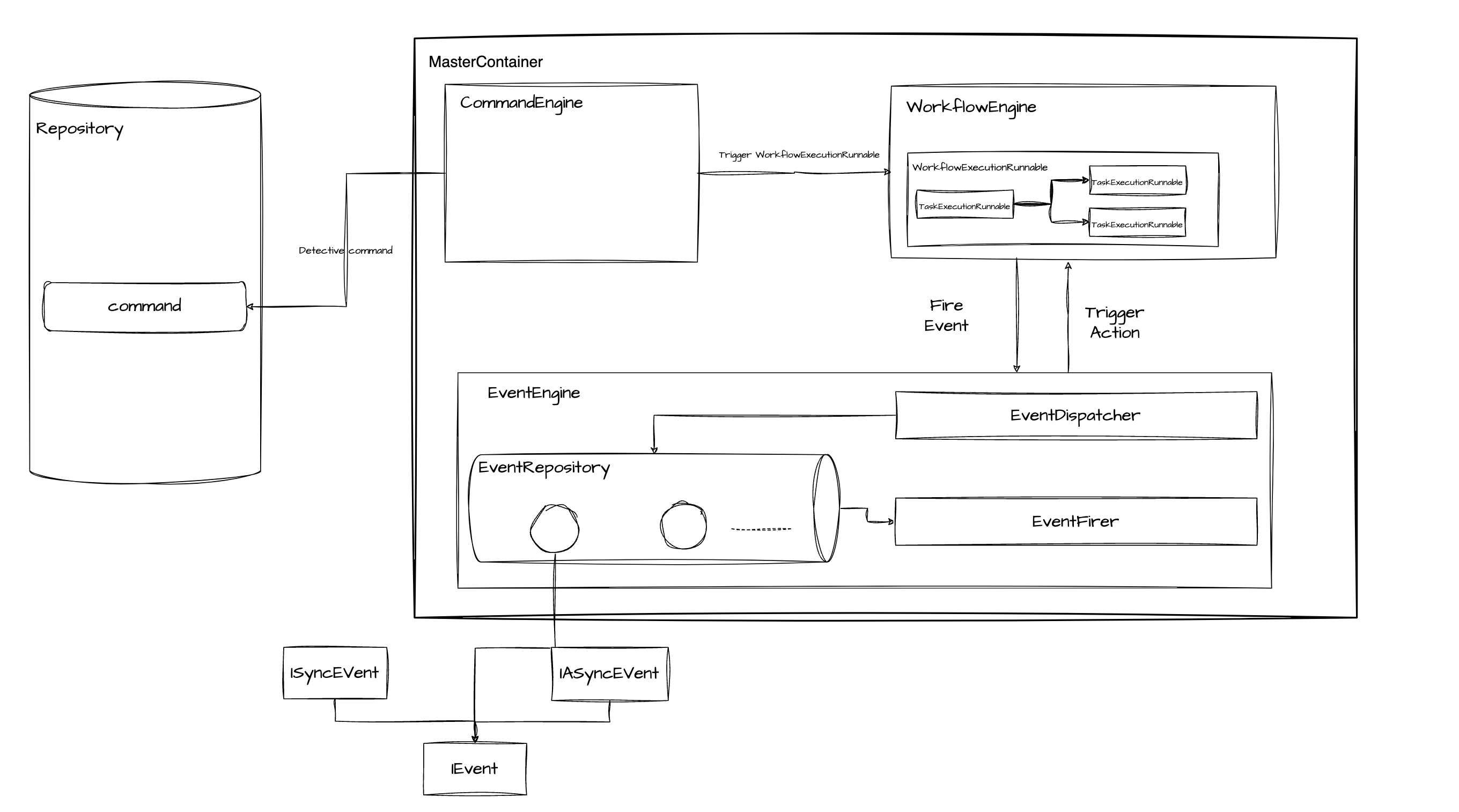
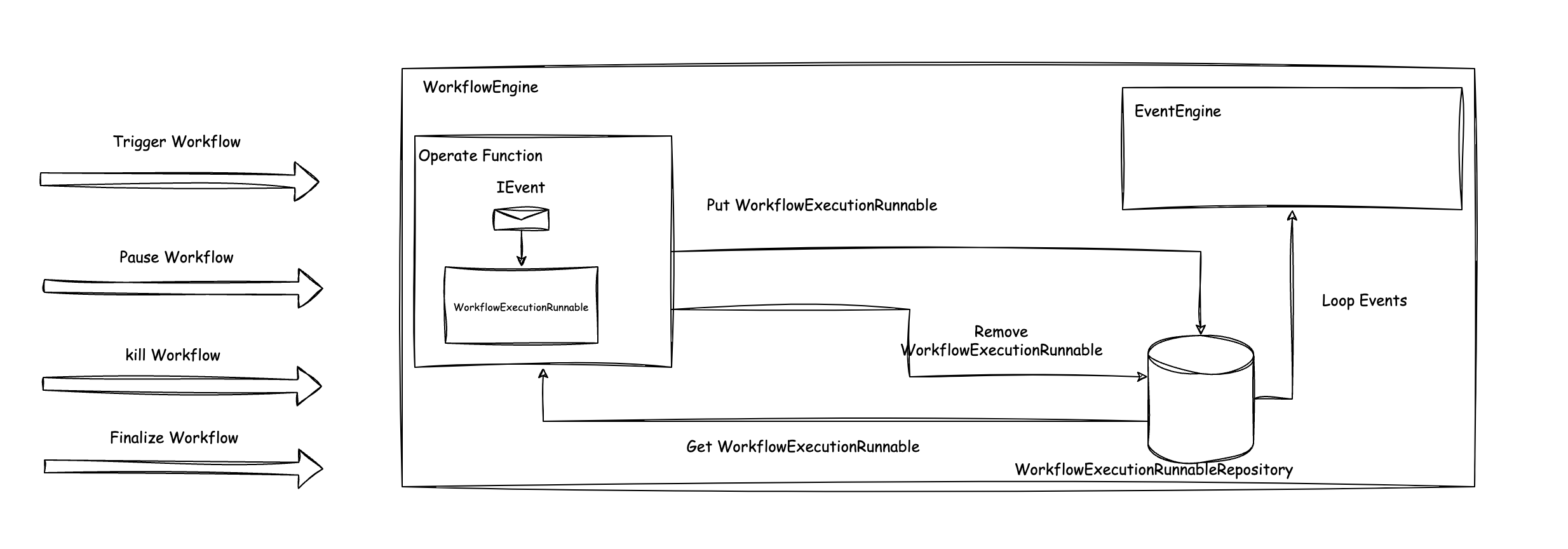
事件线程模型改进
当前,DolphinScheduler Master中存在两个事件线程池,分别处理工作流事件和任务状态变更事件。这样的模型导致运行中很难协调这两个线程池,而且事件的顺序可能会丢失,并且用户也很难去设置这两个线程池的大小。
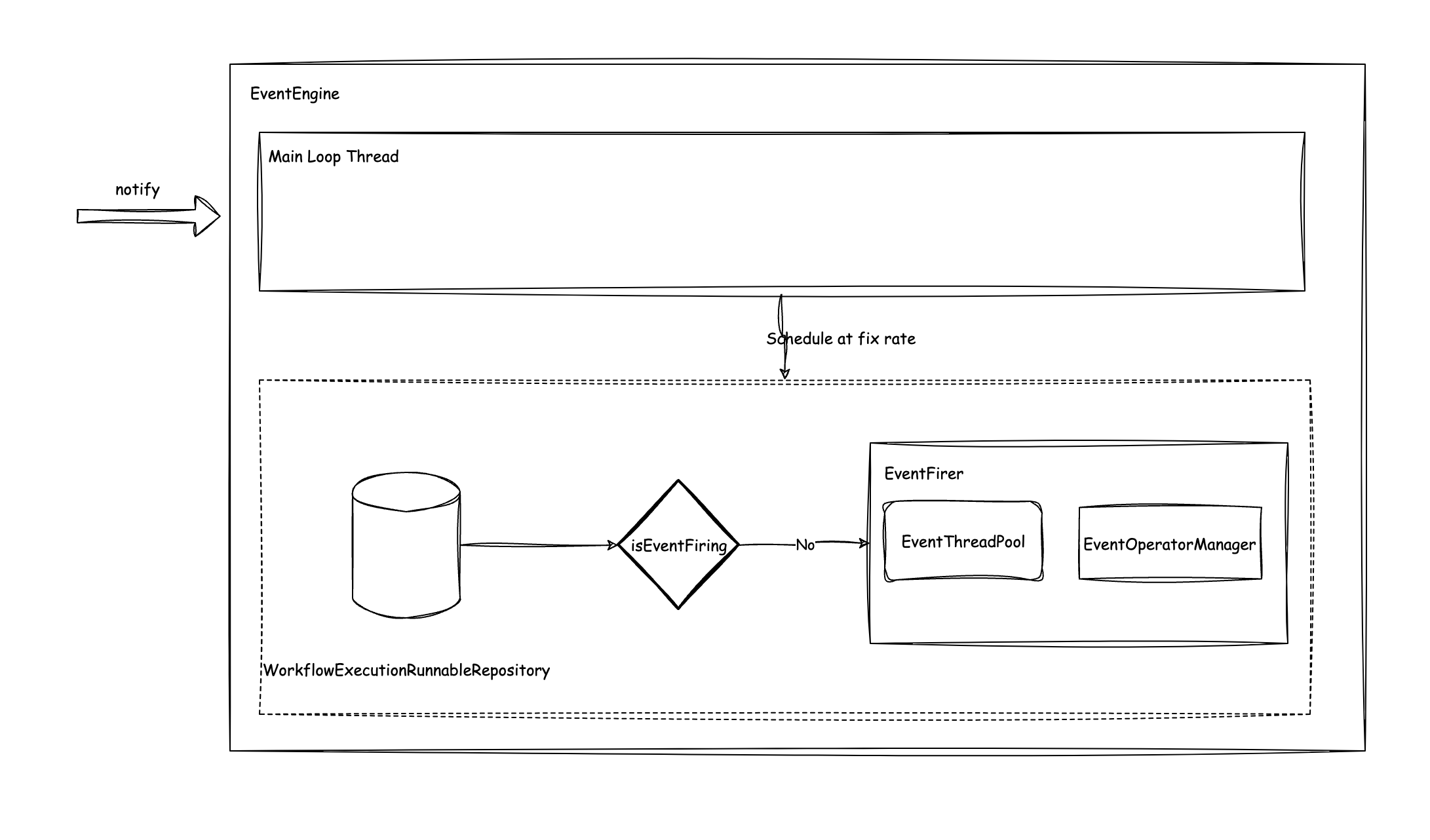
为了改变这一点,3.3.0中做了以下优化:
- 合并两个事件线程池,一个工作流中的所有事件按FIFO顺序在事件队列中处理
- 提供了更多的事件指标和事件查询接口,便于监控和管理工作流事件
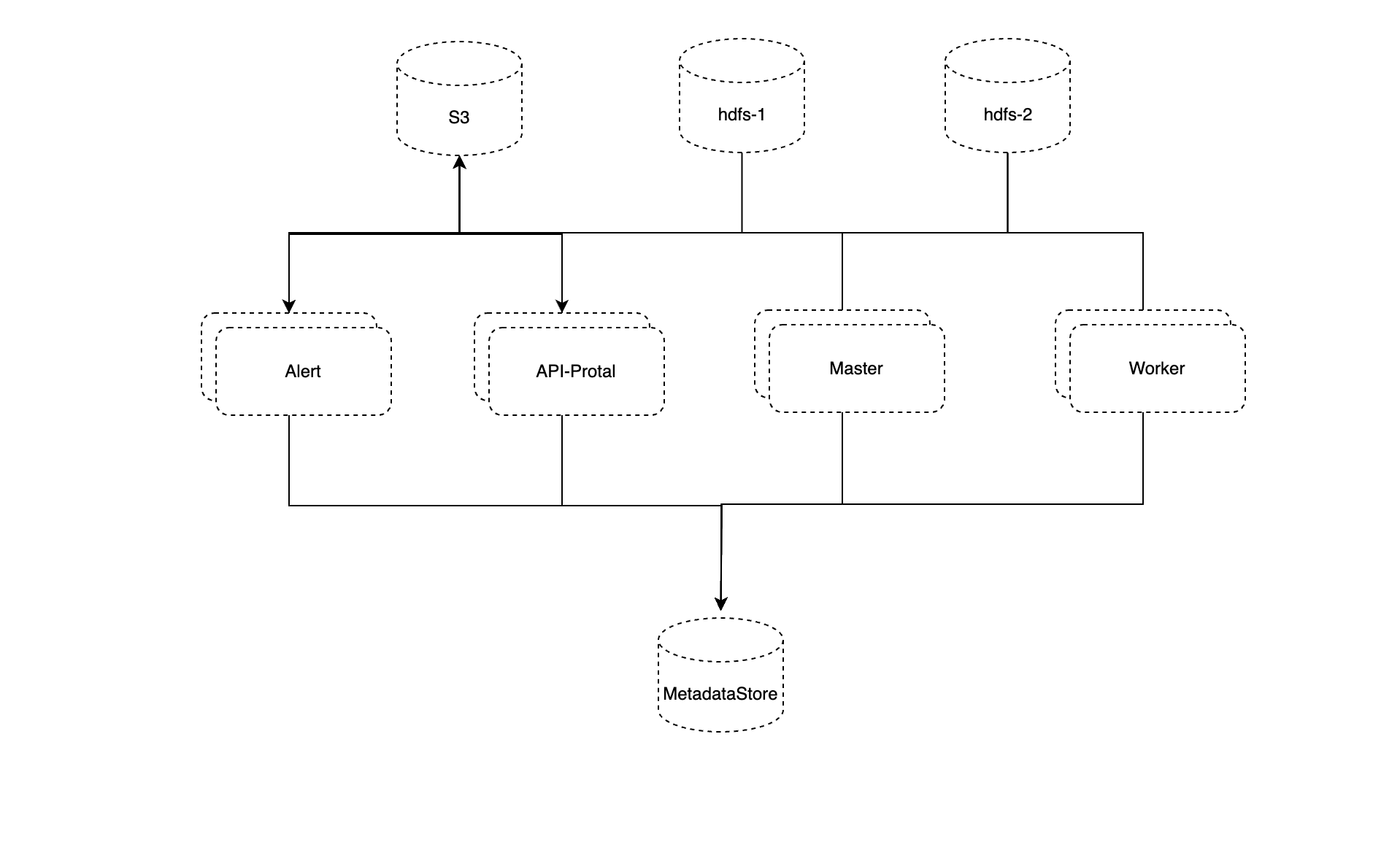
支持接入多个Hadoop/S3集群
3.3.0之前版本中,当当资源中心配置HDFS/S3,配置第三方系统任务时只能通过配置文件去进行配置,这就导致在运行时不能新增Hadoop集群或S3集群。而且配置文件过大。
新版本中这一块有了变化:
- 允许在元数据存储中进行配置
- 支持多个集群
- 支持在运行时添加新集群
- 不同任务可以使用不同的集群

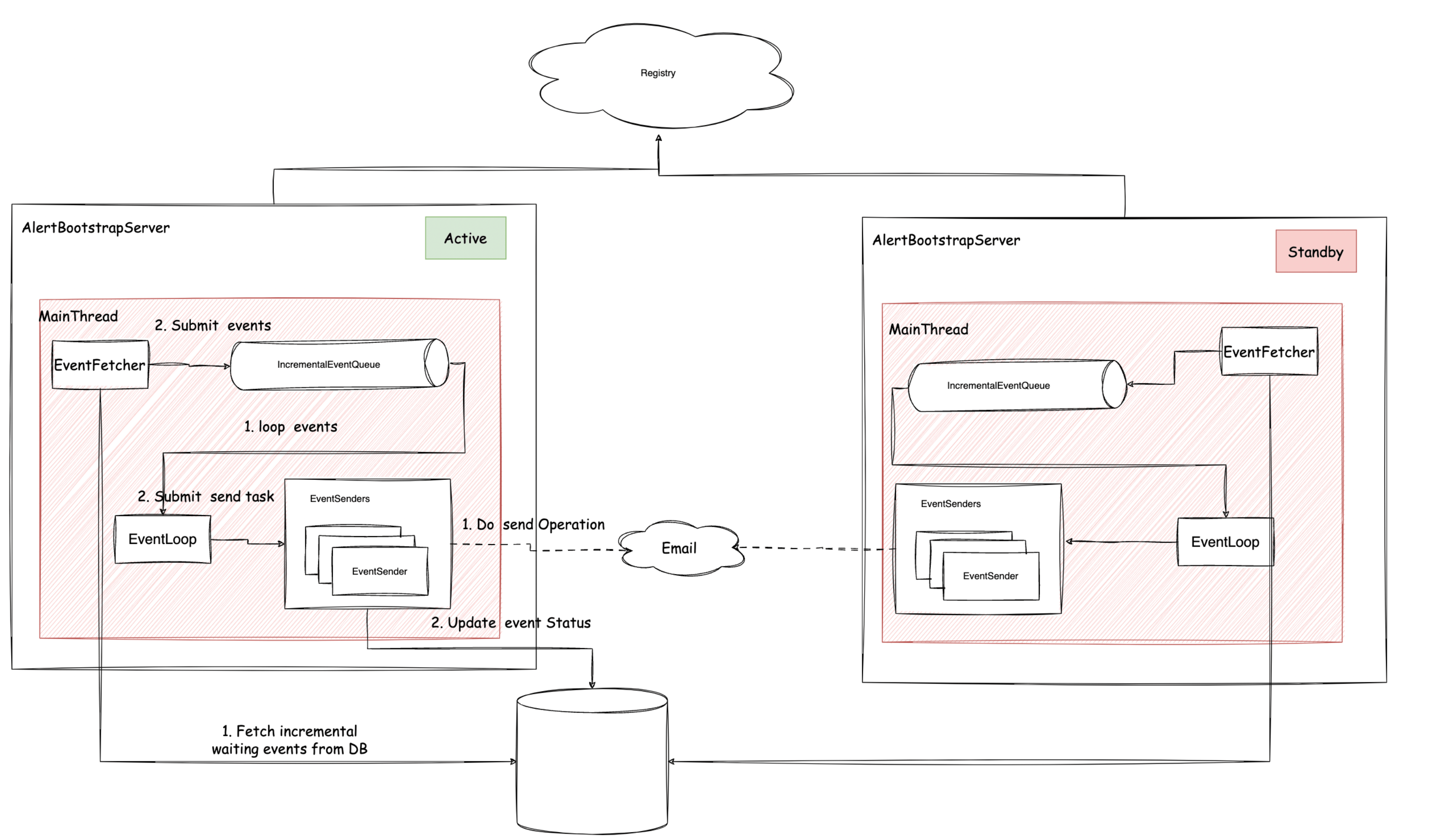
AlertServer改进
AlertServer通过HA实现了高可用,使用单线程发送警报。这就导致需要使用额外的机器来部署AlertServer。
新版本中,允许用户将AlertServer嵌入API服务器,并采用多线程模型发送警报,提高了效率。
以上为Apache DolphinScheduler 3.3.0版本将带来的新功能与优化项参考,具体更新内容请关注官网和GitHub发布消息。
如何参与社区
- 邮件:是讨论问题的首选方式,包括用户和开发者邮件列表,用来讨论使用问题、设计方案、新的想法等,以及新版本发布投票。
- 用户组邮件:[email protected]
- 开发者邮件:[email protected]
- GitHub:是参与项目最简单的方式,包括DolphinScheduler的多个GitHub仓库
- 通过DSIP引入新功能是惟一的渠道
- 提bug和修bug同样重要
- PR越简单越好
- https://github.com/apache/dolphinscheduler
- https://github.com/apache/dolphinscheduler-website
- https://github.com/apache/dolphinscheduler-operator
- https://github.com/apache/dolphinscheduler-sdk-python
- https://github.com/apache/dolphinscheduler
- 注意事项:
- 通过DSIP引入新功能是唯一的渠道
- 汇报bug和修bug同样重要
- PR越简单越好
结语
Apache DolphinScheduler 3.3.0版本带来了多项重要更新,增强了系统的稳定性、扩展性和易用性。我们鼓励社区成员积极参与,共同推动项目的发展。
嘉宾简介
- 姓名:阮文俊
- Title:Apache DolphinScheduler/SeaTunnel/EventMesh PMC 成员
- GitHub:ruanwenjun
- 就职经历:白鲸开源/eBay/拼多多
- 专业领域:专注于分布式系统和微服务中间件
本文由 白鲸开源 提供发布支持!